Paul HoraninSnowflake Builders Blog: Data Engineers, App Developers, AI/ML, & Data ScienceWorking with large JSON files in Snowflake — Part IV! (Now in Python)Introduction3 min read·Mar 8, 2024----
Paul HoraninSnowflake Builders Blog: Data Engineers, App Developers, AI/ML, & Data ScienceSnowflake’s new VSCode plugin is here!Back in February of 2021, I authored a Medium post on how to use Visual Studio Code as an IDE for Snowflake. That article quickly became my…6 min read·Dec 17, 2022--4--4
Paul HoraninSnowflake Builders Blog: Data Engineers, App Developers, AI/ML, & Data ScienceWorking with large JSON files in Snowflake — Part IIIIntroduction6 min read·Jul 25, 2022--1--1
Paul HoraninSnowflake Builders Blog: Data Engineers, App Developers, AI/ML, & Data ScienceWorking with large JSON files in Snowflake (part 2 — sort of…)Introduction5 min read·May 18, 2022--1--1
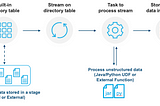
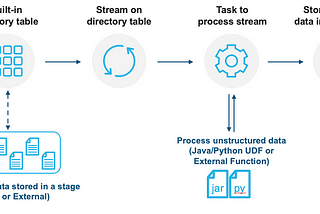
Paul HoraninSnowflake Builders Blog: Data Engineers, App Developers, AI/ML, & Data ScienceUnstructured Data support in SnowflakeIntroduction7 min read·Feb 14, 2022----
Paul Horan"Closed, proprietary data format, vendor lock-in, limited support for semi-structured data, limited…Snowflake suffers from NONE OF THESE issues. Not one. You must be describing some "other" DW platform.1 min read·Jan 14, 2022--1--1
Paul HoraninSnowflake Builders Blog: Data Engineers, App Developers, AI/ML, & Data ScienceIntroducing Serverless Tasks in SnowflakeThe warehouse parameter is no longer tightly coupled with tasks.5 min read·Oct 12, 2021--1--1
Paul HoraninSnowflake Builders Blog: Data Engineers, App Developers, AI/ML, & Data ScienceWorking with XML in Snowflake: Part IVThe saga continues…6 min read·Apr 26, 2021----
Paul HoraninSnowflake Builders Blog: Data Engineers, App Developers, AI/ML, & Data ScienceWorking with XML in Snowflake: Part IIIHow to navigate repeating groups in XML structures with the FLATTEN function and LATERAL join method.5 min read·Apr 12, 2021----
Paul HoraninSnowflake Builders Blog: Data Engineers, App Developers, AI/ML, & Data ScienceWorking with XML in Snowflake: Part IIUsing SQL to query XML4 min read·Apr 10, 2021----